Дискриминантный анализ
Основная цель
Дискриминантный анализ используется для принятия решения о том, какие переменные различают (дискриминируют) две или более возникающие совокупности (группы). Например, некий исследователь в области образования может захотеть исследовать, какие переменные относят выпускника средней школы к одной из трех категорий: (1) поступающий в колледж, (2) поступающий в профессиональную школу или (3) отказывающийся от дальнейшего образования или профессиональной подготовки. Для этой цели исследователь может собрать данные о различных переменных, связанных с учащимися школы. После выпуска большинство учащихся естественно должно попасть в одну из названных категорий. Затем можно использовать Дискриминантный анализ для определения того, какие переменные дают наилучшее предсказание выбора учащимися дальнейшего пути.
Медик может регистрировать различные переменные, относящиеся к состоянию больного, чтобы выяснить, какие переменные лучше предсказывают, что пациент, вероятно, выздоровел полностью (группа 1), частично (группа 2) или совсем не выздоровел (группа 3). Биолог может записать различные характеристики сходных типов (групп) цветов, чтобы затем провести анализ дискриминантной функции, наилучшим образом разделяющей типы или группы.
| В начало |
Вычислительный подход
С вычислительной точки зрения дискриминантный анализ очень похож на дисперсионный анализ (см. раздел Дисперсионный анализ). Рассмотрим следующий простой пример. Предположим, что вы измеряете рост в случайной выборке из 50 мужчин и 50 женщин. Женщины в среднем не так высоки, как мужчины, и эта разница должна найти отражение для каждой группы средних (для переменной Рост). Поэтому переменная Рост позволяет вам провести дискриминацию между мужчинами и женщинами лучше, чем, например, вероятность, выраженная следующими словами: "Если человек большой, то это, скорее всего, мужчина, а если маленький, то это вероятно женщина".
Вы можете обобщить все эти доводы на менее "тривиальные" группы и переменные. Например, предположим, что вы имеете две совокупности выпускников средней школы - тех, кто выбрал поступление в колледж, и тех, кто не собирается это делать. Вы можете собрать данные о намерениях учащихся продолжить образование в колледже за год до выпуска. Если средние для двух совокупностей (тех, кто в настоящее время собирается продолжить образование, и тех, кто отказывается) различны, то вы можете сказать, что намерение поступить в колледж, как это установлено за год до выпуска, позволяет разделить учащихся на тех, кто собирается и кто не собирается поступать в колледж (и эта информация может быть использована членами школьного совета для подходящего руководства соответствующими студентами).
В завершение заметим, что основная идея дискриминантного анализа заключается в том, чтобы определить, отличаются ли совокупности по среднему какой-либо переменной (или линейной комбинации переменных), и затем использовать эту переменную, чтобы предсказать для новых членов их принадлежность к той или иной группе.
Дисперсионный анализ. Поставленная таким образом задача о дискриминантной функции может быть перефразирована как задача одновходового дисперсионного анализа (ANOVA). Можно спросить, в частности, являются ли две или более совокупности значимо отличающимися одна от другой по среднему значению какой-либо конкретной переменной. Для изучения вопроса о том, как можно проверить статистическую значимость отличия в среднем между различными совокупностями, вы можете прочесть раздел Дисперсионный анализ. Однако должно быть ясно, что если среднее значение определенной переменной значимо различно для двух совокупностей, то вы можете сказать, что переменная разделяет данные совокупности.
В случае одной переменной окончательный критерий значимости того, разделяет переменная две совокупности или нет, дает F-критерий. Как описано в разделах Элементарные понятия статистики и Дисперсионный анализ, F статистика по существу вычисляется, как отношение межгрупповой дисперсии к объединенной внутригрупповой дисперсии. Если межгрупповая дисперсия оказывается существенно больше, тогда это должно означать различие между средними.
Многомерные переменные. При применении дискриминантного анализа обычно имеются несколько переменных, и задача состоит в том, чтобы установить, какие из переменных вносят свой вклад в дискриминацию между совокупностями. В этом случае вы имеете матрицу общих дисперсий и ковариаций, а также матрицы внутригрупповых дисперсий и ковариаций. Вы можете сравнить эти две матрицы с помощью многомерного F-критерия для того, чтобы определить, имеются ли значимые различия между группами (с точки зрения всех переменных). Эта процедура идентична процедуре Многомерного дисперсионного анализа (MANOVA). Так же как в MANOVA, вначале можно выполнить многомерный критерий, и затем, в случае статистической значимости, посмотреть, какие из переменных имеют значимо различные средние для каждой из совокупностей. Поэтому, несмотря на то, что вычисления для нескольких переменных более сложны, применимо основное правило, заключающееся в том, что если вы производите дискриминацию между совокупностями, то должно быть заметно различие между средними.
| В начало |
Пошаговый дискриминантный анализ
Вероятно, наиболее общим применением дискриминантного анализа является включение в исследование многих переменных с целью определения тех из них, которые наилучшим образом разделяют совокупности между собой. Например, исследователь в области образования, интересующийся предсказанием выбора, который сделают выпускники средней школы относительно своего дальнейшего образования, произведет с целью получения наиболее точных прогнозов регистрацию возможно большего количества параметров обучающихся, например, мотивацию, академическую успеваемость и т.д.
Модель. Другими словами, вы хотите построить "модель", позволяющую лучше всего предсказать, к какой совокупности будет принадлежать тот или иной образец. В следующем рассуждении термин "в модели" будет использоваться для того, чтобы обозначать переменные, используемые в предсказании принадлежности к совокупности; о неиспользуемых для этого переменных будем говорить, что они "вне модели".
Пошаговый анализ с включением. В пошаговом анализе дискриминантных функций модель дискриминации строится по шагам. Точнее, на каждом шаге просматриваются все переменные и находится та из них, которая вносит наибольший вклад в различие между совокупностями. Эта переменная должна быть включена в модель на данном шаге, и происходит переход к следующему шагу.
Пошаговый анализ с исключением. Можно также двигаться в обратном направлении, в этом случае все переменные будут сначала включены в модель, а затем на каждом шаге будут устраняться переменные, вносящие малый вклад в предсказания. Тогда в качестве результата успешного анализа можно сохранить только "важные" переменные в модели, то есть те переменные, чей вклад в дискриминацию больше остальных.
F для включения, F для исключения. Эта пошаговая процедура "руководствуется" соответствующим значением F для включения и соответствующим значением F для исключения. Значение F статистики для переменной указывает на ее статистическую значимость при дискриминации между совокупностями, то есть, она является мерой вклада переменной в предсказание членства в совокупности. Если вы знакомы с пошаговой процедурой множественной регрессии, то вы можете интерпретировать значение F для включения/исключения в том же самом смысле, что и в пошаговой регрессии.
Расчет на случай. Пошаговый дискриминантный анализ основан на использовании статистического уровня значимости. Поэтому по своей природе пошаговые процедуры рассчитывают на случай, так как они "тщательно перебирают" переменные, которые должны быть включены в модель для получения максимальной дискриминации. При использовании пошагового метода исследователь должен осознавать, что используемый при этом уровень значимости не отражает истинного значения альфа, то есть, вероятности ошибочного отклонения гипотезы H0 (нулевой гипотезы, заключающейся в том, что между совокупностями нет различия).
| В начало |
Интерпретация функции дискриминации для двух групп
Для двух групп дискриминантный анализ может рассматриваться также как процедура множественной регрессии (и аналогичная ей) - (см. раздел Множественная регрессия; дискриминантный анализ для двух групп также называется Линейным дискриминантным анализом Фишера после работы Фишера (Fisher, 1936). (С вычислительной точки зрения все эти подходы аналогичны). Если вы кодируете две группы как 1 и 2, и затем используете эти переменные в качестве зависимых переменных в множественной регрессии, то получите результаты, аналогичные тем, которые получили бы с помощью Дискриминантного анализа. В общем, в случае двух совокупностей вы подгоняете линейное уравнение следующего типа:
Группа = a + b1*x1 + b2*x2 + ... + bm*xm
где a является константой, и b1...bm являются коэффициентами регрессии. Интерпретация результатов задачи с двумя совокупностями тесно следует логике применения множественной регрессии: переменные с наибольшими регрессионными коэффициентами вносят наибольший вклад в дискриминацию.
| В начало |
Дискриминантные функции для нескольких групп
Если имеется более двух групп, то можно оценить более, чем одну дискриминантную функцию подобно тому, как это было сделано ранее. Например, когда имеются три совокупности, вы можете оценить: (1) - функцию для дискриминации между совокупностью 1 и совокупностями 2 и 3, взятыми вместе, и (2) - другую функцию для дискриминации между совокупностью 2 и совокупности 3. Например, вы можете иметь одну функцию, дискриминирующую между теми выпускниками средней школы, которые идут в колледж, против тех, кто этого не делает (но хочет получить работу или пойти в училище), и вторую функцию для дискриминации между теми выпускниками, которые хотят получить работу против тех, кто хочет пойти в училище. Коэффициенты b в этих дискриминирующих функциях могут быть проинтерпретированы тем же способом, что и ранее.
Канонический анализ. Когда проводится дискриминантный анализ нескольких групп, вы не должны указывать, каким образом следует комбинировать группы для формирования различных дискриминирующих функций. Вместо этого, вы можете автоматически определить некоторые оптимальные комбинации переменных, так что первая функция проведет наилучшую дискриминацию между всеми группами, вторая функция будет второй наилучшей и т.д. Более того, функции будут независимыми или ортогональными, то есть их вклады в разделение совокупностей не будут перекрываться. С вычислительной точки зрения система вы проводите анализ канонических корреляций (см. также раздел Каноническая корреляция), которые будут определять последовательные канонические корни и функции. Максимальное число функций будет равно числу совокупностей минус один или числу переменных в анализе в зависимости от того, какое из этих чисел меньше.
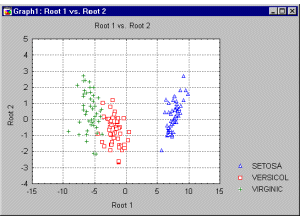
Интерпретация дискриминантных функций. Как было установлено ранее, вы получите коэффициенты b (и стандартизованные коэффициенты бета) для каждой переменной и для каждой дискриминантной (теперь называемой также и канонической) функции. Они могут быть также проинтерпретированы обычным образом: чем больше стандартизованный коэффициент, тем больше вклад соответствующей переменной в дискриминацию совокупностей. (Отметим также, что вы можете также проинтерпретировать структурные коэффициенты; см. ниже.) Однако эти коэффициенты не дают информации о том, между какими совокупностями дискриминируют соответствующие функции. Вы можете определить характер дискриминации для каждой дискриминантной (канонической) функции, взглянув на средние функций для всех совокупностей. Вы также можете посмотреть, как две функции дискриминируют между группами, построив значения, которые принимают обе дискриминантные функции (см., например, следующий график).
В этом примере Корень1 (root1), похоже, в основном дискриминирует между группой Setosa и объединением групп Virginic и Versicol. По вертикальной оси (Корень2) заметно небольшое смещение точек группы Versicol вниз относительно центральной линии (0).
Матрица факторной структуры. Другим способом определения того, какие переменные "маркируют" или определяют отдельную дискриминантную функцию, является использование факторной структуры. Коэффициенты факторной структуры являются корреляциями между переменными в модели и дискриминирующей функцией. Если вы знакомы с факторным анализом (см. раздел Факторный анализ), то можете рассматривать эти корреляции как факторные нагрузки переменных на каждую дискриминантную функцию.
Некоторые авторы согласны с тем, что структурные коэффициенты могут быть использованы при интерпретации реального "смысла" дискриминирующей функции. Объяснения, даваемые этими авторами, заключаются в том, что: (1) - вероятно структура коэффициентов более устойчива и (2) - они позволяют интерпретировать факторы (дискриминирующие функции) таким же образом, как и в факторном анализе. Однако последующие исследования с использованием метода Монте-Карло (Барсиковский и Стивенс (Barcikowski, Stevens, 1975); Хьюберти (Huberty, 1975)) показали, что коэффициенты дискриминантных функций и структурные коэффициенты почти одинаково нестабильны, пока значение размер выборки не станет достаточно большим (например, если число наблюдений в 20 раз больше, чем число переменных). Важно помнить, что коэффициенты дискриминантной функции отражают уникальный (частный) вклад каждой переменной в отдельную дискриминантную функцию, в то время как структурные коэффициенты отражают простую корреляцию между переменными и функциями. Если дискриминирующей функции хотят придать отдельные "осмысленные" значения (родственные интерпретации факторов в факторном анализе), то следует использовать (интерпретировать) структурные коэффициенты. Если же хотят определить вклад, который вносит каждая переменная в дискриминантную функцию, то используют коэффициенты (веса) дискриминантной функции.
Значимость дискриминантной функции. Можно проверить число корней, которое добавляется значимо к дискриминации между совокупностями. Для интерпретации могут быть использованы только те из них, которые будут признаны статистически значимыми. Остальные функции (корни) должны быть проигнорированы.
Итог. Итак, при интерпретации дискриминантной функции для нескольких совокупностей и нескольких переменных, вначале хотят проверить значимость различных функций и в дальнейшем использовать только значимые функции. Затем, для каждой значащей функции вы должны рассмотреть для каждой переменной стандартизованные коэффициенты бета. Чем больше стандартизованный коэффициент бета, тем большим является относительный собственный вклад переменной в дискриминацию, выполняемую соответствующей дискриминантной функцией. В порядке получения отдельных "осмысленных" значений дискриминирующих функций можно также исследовать матрицу факторной структуры с корреляциями между переменными и дискриминирующей функцией. В заключение, вы должны посмотреть на средние для значимых дискриминирующих функций для того, чтобы определить, какие функции и между какими совокупностями проводят дискриминацию.
| В начало |
Предположения
Как говорилось ранее, дискриминантный анализ в вычислительном смысле очень похож на многомерный дисперсионный анализ (MANOVA), и поэтому применимы все предположения для MANOVA, упомянутые в разделе Дисперсионный анализ. Фактически, вы можете использовать широкий набор диагностических правил и статистических критериев для проверки предположений, чтобы вы имели законные основания применения Дискриминантного анализа к вашим данным.
Нормальное распределение. Предполагается, что анализируемые переменные представляют выборку из многомерного нормального распределения. Поэтому вы можете проверить, являются ли переменные нормально распределенными. Отметим, однако, что пренебрежение условием нормальности обычно не является "фатальным" в том смысле, что результирующие критерии значимости все еще "заслуживают доверия". Вы также можете воспользоваться специальными критериями нормальности и графиками.
Однородность дисперсий/ковариаций. Предполагается, что матрицы дисперсий/ковариаций переменных однородны. Как и ранее, малые отклонения не фатальны, однако прежде чем сделать окончательные выводы при важных исследованиях, неплохо обратить внимание на внутригрупповые матрицы дисперсий и корреляций. В частности, можно построить матричную диаграмму рассеяния, весьма полезную для этой цели. При наличии сомнений попробуйте произвести анализ заново, исключив одну или две малоинтересных совокупности. Если общий результат (интерпретация) сохраняется, то вы, по-видимому, имеете разумное решение. Вы можете также использовать многочисленные критерии и способы для того, чтобы проверить, нарушено это предположение в ваших данных или нет. Однако, как упомянуто в разделе Дисперсионный анализ, многомерный M-критерий Бокса для проверки однородности матриц дисперсий/ковариаций, в частности, чувствителен к отклонению от многомерной нормальности и не должен восприниматься слишком "серьезно".
Корреляции между средними и дисперсиями. Большинство "реальных" угроз корректности применения критериев значимости возникает из-за возможной зависимости между средними по совокупностям и дисперсиями (или стандартными отклонениями) между собой. Интуитивно ясно, что если имеется большая изменчивость в совокупности с высокими средними в нескольких переменных, то эти высокие средние ненадежны. Однако критерии значимости основываются на объединенных дисперсиях, то есть, на средней дисперсии по всем совокупностям. Поэтому критерии значимости для относительно больших средних (с большими дисперсиями) будут основаны на относительно меньших объединенных дисперсиях и будут ошибочно указывать на статистическую значимость. На практике этот вариант может произойти также, если одна из изучаемых совокупностей содержит несколько экстремальных выбросов, которые сильно влияют на средние и, таким образом, увеличивают изменчивость. Для определения такого случая следует изучить описательные статистики, то есть средние и стандартные отклонения или дисперсии для таких корреляций.
Задача с плохо обусловленной матрицей. Другое предположение в дискриминантном анализе заключается в том, что переменные, используемые для дискриминации между совокупностями, не являются полностью избыточными. При вычислении результатов дискриминантного анализа происходит обращение матрицы дисперсий/ковариаций для переменных в модели. Если одна из переменных полностью избыточна по отношению к другим переменным, то такая матрица называется плохо обусловленной и не может быть обращена. Например, если переменная является суммой трех других переменных, то это отразится также и в модели, и рассматриваемая матрица будет плохо обусловленной.
Значения толерантности. Чтобы избежать плохой обусловленности матриц, необходимо постоянно проверять так называемые значения толерантности для каждой переменной. Значение толерантности вычисляется как 1 минус R-квадрат, где R-квадрат - коэффициент множественной корреляции для соответствующей переменной со всеми другими переменными в текущей модели. Таким образом, это есть доля дисперсии, относящаяся к соответствующей переменной. Вы можете также обратиться к разделу Множественная регрессия, чтобы узнать больше о методах множественной регрессии и об интерпретации значения толерантности. В общем случае, когда переменная почти полностью избыточна (и поэтому матрица задачи является плохо обусловленной), значение толерантности для этой переменной будет приближаться к нулю.
| В начало |
Классификация
Другой главной целью применения дискриминантного анализа является проведение классификации. Как только модель установлена и получены дискриминирующие функции, возникает вопрос о том, как хорошо они могут предсказывать, к какой совокупности принадлежит конкретный образец?
Априорная и апостериорная классификация. Прежде чем приступить к изучению деталей различных процедур оценивания, важно уяснить, что эта разница ясна. Обычно, если вы оцениваете на основании некоторого множества данных дискриминирующую функцию, наилучшим образом разделяющую совокупности, и затем используете те же самые данные для оценивания того, какова точность вашей процедуры, то вы во многом полагаетесь на волю случая. В общем случае, получают, конечно худшую классификацию для образцов, не использованных для оценки дискриминантной функции. Другими словами, классификация действует лучшим образом для выборки, по которой была проведена оценка дискриминирующей функции (апостериорная классификация), чем для свежей выборки (априорная классификация). (Трудности с (априорной) классификацией будущих образцов заключается в том, что никто не знает, что может случиться. Намного легче классифицировать уже имеющиеся образцы.) Поэтому оценивание качества процедуры классификации никогда не производят по той же самой выборке, по которой была оценена дискриминирующая функция. Если желают использовать процедуру для классификации будущих образцов, то ее следует "испытать" (произвести кросс-проверку) на новых объектах.
Функции классификации. Функции классификации не следует путать с дискриминирующими функциями. Функции классификации предназначены для определения того, к какой группе наиболее вероятно может быть отнесен каждый объект. Имеется столько же функций классификации, сколько групп. Каждая функция позволяет вам для каждого образца и для каждой совокупности вычислить веса классификации по формуле:
Si = ci + wi1*x1 + wi2*x2 + ... + wim*xm
В этой формуле индекс i обозначает соответствующую совокупность, а индексы 1, 2, ..., m обозначают m переменных; ci являются константами для i-ой совокупности, wij - веса для j-ой переменной при вычислении показателя классификации для i-ой совокупности; xj - наблюдаемое значение для соответствующего образца j-ой переменной. Величина Si является результатом показателя классификации.
Поэтому вы можете использовать функции классификации для прямого вычисления показателя классификации для некоторых новых значений.
Классификация наблюдений. Как только вы вычислили показатели классификации для наблюдений, легко решить, как производить классификацию наблюдений. В общем случае наблюдение считается принадлежащим той совокупности, для которой получен наивысший показатель классификации (кроме случая, когда вероятности априорной классификации становятся слишком малыми; см. ниже). Поэтому, если вы изучаете выбор карьеры или образования учащимися средней школы после выпуска (поступление в колледж, в профессиональную школу или получение работы) на основе нескольких переменных, полученных за год до выпуска, то можете использовать функции классификации, чтобы предсказать, что наиболее вероятно будет делать каждый учащийся после выпуска. Однако вы хотели бы определить вероятность, с которой учащийся сделает предсказанный выбор. Эти вероятности называются апостериорными, и их также можно вычислить. Однако для понимания, как эти вероятности вычисляются, вначале рассмотрим так называемое расстояние Махаланобиса.
Расстояние Махаланобиса. Вы можете прочитать об этих расстояниях в других разделах. В общем, расстояние Махаланобиса является мерой расстояния между двумя точками в пространстве, определяемым двумя или более коррелированными переменными. Например, если имеются всего две некоррелированных переменные, то вы можете нанести точки (образцы) на стандартную 2М диаграмму рассеяния. Расстояние Махаланобиса между точками будет в этом случае равно расстоянию Евклида, т.е. расстоянию, измеренному, например, рулеткой. Если имеются три некоррелированные переменные, то для определения расстояния вы можете по-прежнему использовать рулетку (на 3М диаграмме). При наличии более трех переменных вы не можете более представить расстояние на диаграмме. Также и в случае, когда переменные коррелированы, то оси на графике могут рассматриваться как неортогональные (они уже не направлены под прямыми углами друг к другу). В этом случае простое определение расстояния Евклида не подходит, в то время как расстояние Махаланобиса является адекватно определенным в случае наличия корреляций.
Расстояние Махаланобиса и классификация. Для каждой совокупности в выборке вы можете определить положение точки, представляющей средние для всех переменных в многомерном пространстве, определенном переменными рассматриваемой модели. Эти точки называются центроидами группы. Для каждого наблюдения вы можете затем вычислить его расстояние Махаланобиса от каждого центроида группы. Снова, вы признаете наблюдение принадлежащим к той группе, к которой он ближе, т.е. когда расстояние Махаланобиса до нее минимально.
Апостериорные вероятности классификации. Используя для классификации расстояние Махаланобиса, вы можете теперь получить вероятность того, что образец принадлежит к конкретной совокупности. Это значение будет не вполне точным, так как распределение вокруг среднего для каждой совокупности будет не в точности нормальным. Так как принадлежность каждого образца вычисляется по априорному знанию модельных переменных, эти вероятности называются апостериорными вероятностями. Короче, апостериорные вероятности - это вероятности, вычисленные с использованием знания значений других переменных для образцов из частной совокупности. Некоторые пакеты автоматически вычисляют эти вероятности для всех наблюдений (или для выбранных наблюдений при проведении кросс-проверки).
Априорные вероятности классификации. Имеется одно дополнительное обстоятельство, которое следует рассмотреть при классификации образцов. Иногда вы знаете заранее, что в одной из групп имеется больше наблюдений, чем в другой. Поэтому априорные вероятности того, что образец принадлежит такой группе, выше. Например, если вы знаете заранее, что 60% выпускников вашей средней школы обычно идут в колледж, (20% идут в профессиональные школы и остальные 20% идут работать), то вы можете уточнить предсказание таким образом: при всех других равных условиях более вероятно, что учащийся поступит в колледж, чем сделает два других выбора. Вы можете установить различные априорные вероятности, которые будут затем использоваться для уточнения результатов классификации наблюдений (и для вычисления апостериорных вероятностей).
На практике, исследователю необходимо задать себе вопрос, является ли неодинаковое число наблюдений в различных совокупностях в первоначальной выборке отражением истинного распределения в популяции, или это только (случайный) результат процедуры выбора. В первом случае вы должны положить априорные вероятности пропорциональными объемам совокупностей в выборке; во втором - положить априорные вероятности одинаковыми для каждой совокупности. Спецификация различных априорных вероятностей может сильно влиять на точность классификации.
Итог классификации. Общим результатом, на который следует обратить внимание при оценке качества текущей функции классификации, является матрица классификации. Матрица классификации содержит число образцов, корректно классифицированных (на диагонали матрицы) и тех, которые попали не в свои совокупности (группы).
Другие предостережения. При повторной итерации апостериорная классификация того, что случилось в прошлом, не очень трудна. Нетрудно получить очень хорошую классификацию тех образцов, по которым была оценена функция классификации. Для получения сведений, насколько хорошо работает процедура классификации на самом деле, следует классифицировать (априорно) различные наблюдения, то есть, наблюдения, которые не использовались при оценке функции классификации. Вы можете гибко использовать условия отбора для включения или исключения из вычисления наблюдений, поэтому матрица классификации может быть вычислена по "старым" образцам столь же успешно, как и по "новым". Только классификация новых наблюдений позволяет определить качество функции классификации (см. также кросс-проверку); классификация старых наблюдений позволяет лишь провести успешную диагностику наличия выбросов или области, где функция классификации кажется менее адекватной.
Итог. В общем, Дискриминантный анализ - это очень полезный инструмент (1) - для поиска переменных, позволяющих относить наблюдаемые объекты в одну или несколько реально наблюдаемых групп, (2) - для классификации наблюдений в различные группы.
| В начало |
![]()
(c) Copyright StatSoft, Inc., 1984-1998
STATISTICA является торговой маркой StatSoft, Inc.